Synthesis of facial expressions is central to computer facial animation, and has experienced increased attention for its important applications in entertainment
(e.g. movies and computer games), advanced man-machine interfaces, electronic commence, tele-presence and shared virtual world systems, and facial expression recognition. Advances in facial animation systems show the potential of physics-based approaches, where an anatomically accurate model of facial musculature, passive tissues and underlying skeletal structure is simulated. This kind of techniques can be used to create detailed, realistic animations. However, as the model becomes more complex, animating detailed models of this sort becomes more difficult, requiring complex coordinated stimulation of the underlying musculature. Although the Facial Action Coding System (FACS) that codes facial movements in small units provides guidance to activate individual muscles for synthesizing specific expressions, extensive manual intervention is still required due to the difficulty in determining appropriate muscle parameter values. Once a model exists, it is often desirable to automatically determine muscle contractions from real facial motion data.
One solution to this problem comes from the performance-driven animation approach, in which video footage recording the performance of a human actor is used to control the animation of a synthetic model. The face can be tracked throughout the video by recovering the position and expression at each frame. This information can then be used to estimate animation parameter values. While various techniques have been used for performance-driven animation, most existing ones use colored markers painted on the actor’s face to aid the face tracker. Once the position of the markers has been determined, the position of the face and the facial features can be derived easily. However, the use of markers on the face is intrusive and limits the type of video that can be processed.
Figure 1: Overview of the example-based performance-driven expression synthesis system.
We propose an example-based performance-driven animation method by automatically determining facial muscle activations that track markerless video footage of a person’s face. Our method consists of several stages: facial deformation subspace construction, facial motion tracking, and expression retargeting. Fig. 1 shows a block diagram of the system architecture. In facial deformation subspace construction, we build a low-dimensional linear subspace that models image variation due to non-rigid facial deformations. The subspace is trained offline by processing a video sequence of the person with different expressions. In face tracking procedure, the deformation subspace model is incorporated into an efficient tracking algorithm which establishes temporal correspondence of the face region in the video sequence by simultaneously determining both motion and appearance parameters with no more computation that would be required. During the training phase of the tracking algorithm a set of templates associated to the subspace basis is computed to alleviate the online computation. For expression retargeting, a set of example face images that show key expressions are selected. Their appearance parameters in the facial deformation subspace together with the corresponding animation parameters of an anatomical 3D face model are used to learn the relationship between the animation parameters and the appearance parameters. At runtime, upon receiving the appearance parameters from the tracker, the expression retargeting only needs a matrix multiply to obtain the animation parameters, allowing the face model to be animated at interactive rates.
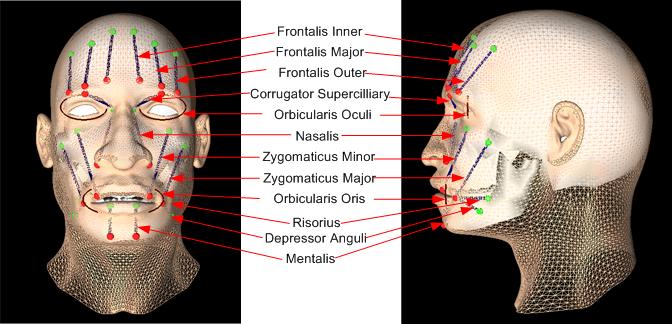
The anatomy-based face model. Left: face geometry. Right: multi-layer anatomical structure
of the skin, muscles and skull.
Examples of key expressions.
Positioning of feature points for a training frame.
Some tracking frames from the synthetic sequence.
Errors of estimated animation parameters.
Example frames from two live tracking sequences and expressions synthesized on the 3D
face model.
Papers:
Yu Zhang. "Example-based performance-driven animation of an anatomical face model". In J. S. Wright and L. M. Hughes (ed.), Computer Animation, pp. 129-144, Nova Science Publishers, NY, 2011.
Yu Zhang, Meng Luo and Shuhong Xu. "An efficient markerless method for resynthesizing facial animation on an anatomy-based model". Proc. IEEE International Conference on Multimedia & Expo 2007 (ICME2007), pp. 971-974, Beijing, China, July 2007.
Copyright 2005-2013, Yu
Zhang. This material may not be published, modified or otherwise
redistributed in whole or part without prior approval.